


Un querido colega cono comparte el presente artículo escrito por Daegan Miller, publicado en noviembre 1 de 2024 en la sección de investigación del boletín de noticias de la University of Massachusetts Amherst y traducido por nosotros para este espacio. Veamos de que se trata….
El motor de búsqueda de Internet del futuro estará impulsado por inteligencia artificial. Ya se puede elegir entre una gran cantidad de motores de búsqueda impulsados o mejorados por IA, aunque su fiabilidad a menudo deja mucho que desear. Sin embargo, un equipo de científicos informáticos de la Universidad de Massachusetts Amherst publicó y lanzó recientemente un nuevo sistema para evaluar la fiabilidad de las búsquedas generadas por IA.
El método, denominado "eRAG", es una forma de poner a la IA y al motor de búsqueda en diálogo entre sí, para luego evaluar la calidad de los motores de búsqueda para el uso de la IA. El trabajo se publica como parte de las Actas de la 47.ª Conferencia Internacional ACM SIGIR sobre Investigación y Desarrollo en Recuperación de Información.


"Todos los motores de búsqueda que hemos utilizado siempre fueron diseñados para humanos", afirma Alireza Salemi, estudiante de posgrado en el Manning College of Information and Computer Sciences de UMass Amherst y autor principal del artículo.
"Funcionan bastante bien cuando el usuario es un humano, pero el motor de búsqueda del usuario principal del futuro será uno de los grandes modelos de lenguaje (LLM, por sus siglas en inglés) de IA, como ChatGPT. Esto significa que necesitamos rediseñar por completo la forma en que funcionan los motores de búsqueda, y mi investigación explora cómo los LLM y los motores de búsqueda pueden aprender unos de otros".

El problema básico al que se enfrentan Salemi y el autor principal de la investigación, Hamed Zamani, profesor asociado de informática y ciencias de la información en UMass Amherst, es que los humanos y los LLM tienen necesidades de información y comportamientos de consumo muy diferentes.
Por ejemplo, si no recuerdas bien el título y el autor de ese nuevo libro que acaba de publicarse, puedes introducir una serie de términos de búsqueda generales, como "¿cuál es la nueva novela de espías con un toque medioambiental de ese famoso escritor?" y luego limitar los resultados, o realizar otra búsqueda a medida que recuerdas más información (el autor es una mujer que escribió la novela " Flamethrowers"), hasta que encuentres el resultado correcto ("Creation Lake" de Rachel Kushner, que Google arrojó como el tercer resultado después de seguir el proceso anterior).
Pero así es como trabajan los humanos, no los LLM. Están entrenados con conjuntos de datos específicos y enormes, y todo lo que no esté en ese conjunto de datos, como el nuevo libro que acaba de llegar a los estantes, es efectivamente invisible para el LLM.
Además, no son particularmente fiables con solicitudes confusas, porque el LLM necesita poder pedir más información al motor; pero para ello, necesita saber qué información adicional debe pedir.

Los científicos informáticos han ideado una forma de ayudar a los LLM a evaluar y elegir la información que necesitan, llamada "generación aumentada por recuperación" o RAG. RAG es una forma de aumentar los LLM con las listas de resultados producidas por los motores de búsqueda. Pero, por supuesto, la pregunta es: ¿cómo evaluar la utilidad de los resultados de recuperación para los LLM?
Hasta ahora, los investigadores han ideado tres formas principales de hacerlo: la primera es obtener de forma colectiva la precisión de los juicios de relevancia con un grupo de humanos. Sin embargo, es un método muy costoso y los humanos pueden no tener el mismo sentido de relevancia que un LLM.

También se puede hacer que un LLM genere un juicio de relevancia, lo que es mucho más barato, pero la precisión se ve afectada a menos que se tenga acceso a uno de los modelos LLM más potentes. El tercer método, que es el estándar de oro, es evaluar el rendimiento de extremo a extremo de los LLM con recuperación aumentada.
Pero incluso este tercer método tiene sus inconvenientes. "Es muy caro", dice Salemi, "y hay algunos problemas de transparencia preocupantes. No sabemos cómo el LLM llegó a sus resultados; solo sabemos que lo hizo o no". Además, existen unas pocas docenas de LLM en este momento, y cada uno de ellos funciona de diferentes maneras, devolviendo diferentes respuestas.

En cambio, Salemi y Zamani han desarrollado eRAG, que es similar al método estándar de oro, pero mucho más rentable, hasta tres veces más rápido, utiliza 50 veces menos energía de GPU y es casi tan confiable.
"El primer paso para desarrollar motores de búsqueda efectivos para agentes de IA es evaluarlos con precisión", dice Zamani. "eRAG proporciona una metodología de evaluación confiable, relativamente eficiente y efectiva para los motores de búsqueda que están siendo utilizados por agentes de IA".
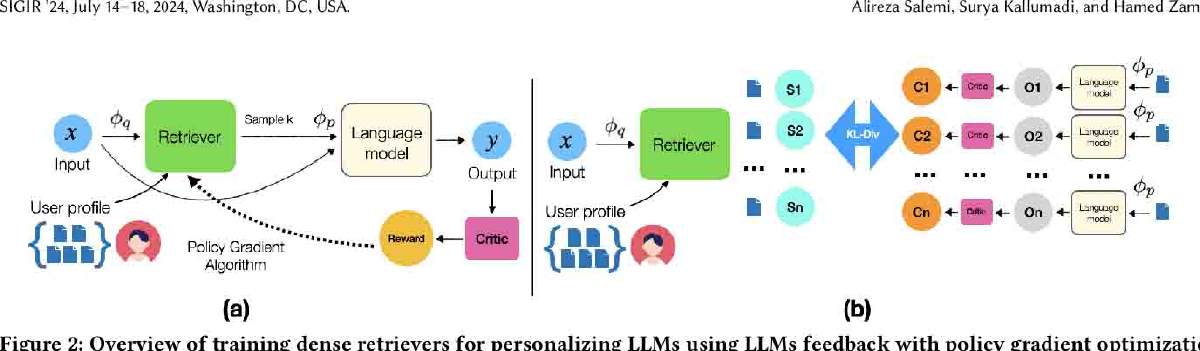
En resumen, eRAG funciona de la siguiente manera: un usuario humano utiliza un agente de IA con tecnología LLM para realizar una tarea. El agente de IA enviará una consulta a un motor de búsqueda y este devolverá una cantidad discreta de resultados (por ejemplo, 50) para el consumo de LLM.
eRAG ejecuta cada uno de los 50 documentos a través de LLM para averiguar qué documento específico encontró útil el LLM para generar el resultado correcto. Luego, estas puntuaciones a nivel de documento se agregan para evaluar la calidad del motor de búsqueda para el agente de IA.
Si bien actualmente no existe un motor de búsqueda que pueda funcionar con todos los principales LLM que se han desarrollado, la precisión, la rentabilidad y la facilidad con la que se puede implementar eRAG es un gran paso hacia el día en que todos nuestros motores de búsqueda funcionen con IA.

Esta investigación ha sido galardonada con el premio al mejor artículo breve de la Conferencia internacional sobre investigación y desarrollo en recuperación de información (SIGIR 2024) de la Asociación de Maquinaria Informática. Un paquete público de Python, que contiene el código para eRAG, está disponible en https://github.com/alirezasalemi7/eRAG.
Fuente: https://www.umass.edu/news/article/who-or-what-searches-search-engines-future

